import pandas as pd
s3_credentials = pd.read_csv('~/Downloads/rootkey.csv')
access_key = s3_credentials.iloc[0,0]
secret = s3_credentials.iloc[0,1]Setting up python and install packages in requirements.txt
Backup to Amazon AWS S3
The S3 service from Amazon Web Services (AWS) is a cloud file-system that provides upload/download to files from the command line and many programming languages.
In the command line, https://github.com/s3tools/s3cmd. In python/pandas, we can use the following.
Account and credentials
- The first step is to create an AWS account.
- Next, go to the S3 service in the AWS website after creating your account, and create a
bucketto host file. In the example below, the bucket name isdata-science-rutgers-spring-2024. - Finally, you will need to create an
access keyand associatedsecretin the AWS website in account settings undersecurity credentials.
Writing files to S3 from python and pandas
rates_df = pd.read_csv('rates.csv')
rates_df.head()| Time | USD | JPY | BGN | CZK | DKK | GBP | CHF | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2024-04-16 | 1.0637 | 164.54 | 1.9558 | 25.210 | 7.4609 | 0.85440 | 0.9712 |
| 1 | 2024-04-15 | 1.0656 | 164.05 | 1.9558 | 25.324 | 7.4606 | 0.85405 | 0.9725 |
| 2 | 2024-04-12 | 1.0652 | 163.16 | 1.9558 | 25.337 | 7.4603 | 0.85424 | 0.9716 |
| 3 | 2024-04-11 | 1.0729 | 164.18 | 1.9558 | 25.392 | 7.4604 | 0.85525 | 0.9787 |
| 4 | 2024-04-10 | 1.0860 | 164.89 | 1.9558 | 25.368 | 7.4594 | 0.85515 | 0.9810 |
rates_df.to_csv(
f"s3://data-science-rutgers-spring-2024/rates_backup_another.csv",
index=False,
storage_options={
"key": access_key,
"secret": secret,
})rates_df.to_excel(
f"s3://data-science-rutgers-spring-2024/rates_backup_another.xlsx",
index=False,
storage_options={
"key": access_key,
"secret": secret,
})rates_df.to_json(
f"s3://data-science-rutgers-spring-2024/rates_backup_another.json",
storage_options={
"key": access_key,
"secret": secret,
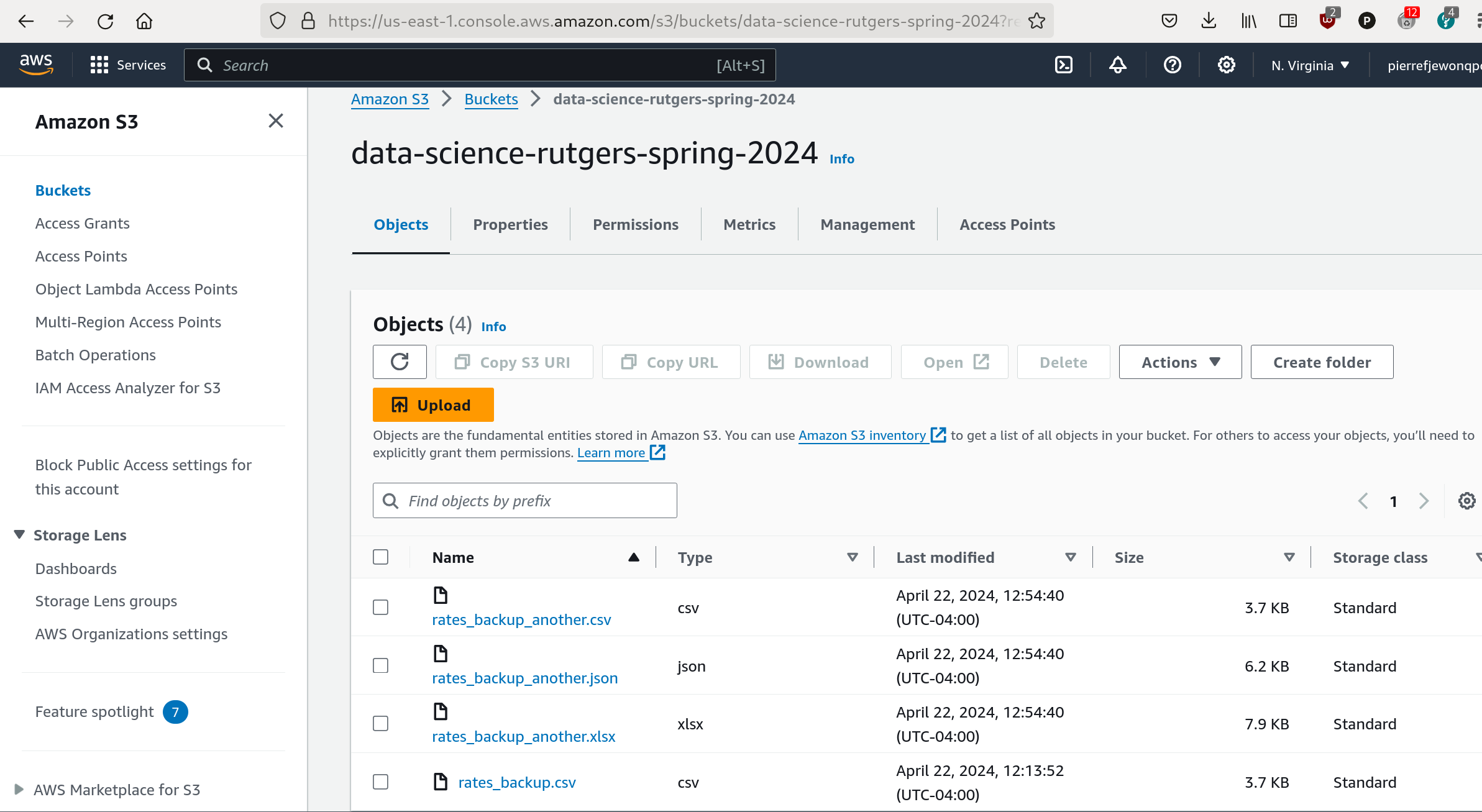
})Backups can then be seen in the AWS S3 console