Create ‘groups’ or ‘splits’ of the data, for instance:
along groups based on some categorical variables
along rolling windows for timeseries data
Apply (aggregate, transform, filter)
Aggregation: compute a summary statistic (or statistics) for each group.
→ Compute group sums or means, or size/counts within each groups
Transformation: perform some group-specific computations and return a like-indexed object. Some examples:
→ Standardize data (zscore or subtracting the min and dividing by max-min) within a group.
→ Filling NAs within groups with a value derived from each group (e.g., the mean within the group)
Filtration: discard some groups, according to a group-wise computation that evaluates to True or False. Some examples:
→ Discard data that belong to groups with fewver than 10 rows.
→ Filter out groups that have more than 30% of missing data.
Combine
After the aggregation, transformation or filtration is done, combine the data back together as one:
Combine the aggregated summary statistics of all groups in a pivot table
Combine the transformed columns back into a data-frame of the same length as the original one
After a filtration, get back the original data, with the filtered out rows discarded
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsdf = pd.read_csv('rates.csv')df.index = df['Time'].astype(np.dtype('datetime64[ns]'))df = df.drop(columns='Time')df = df.sort_index()df.head()
USD
JPY
BGN
CZK
DKK
GBP
CHF
Time
2024-01-18
1.0875
160.89
1.9558
24.734
7.4571
0.85773
0.9432
2024-01-19
1.0887
161.17
1.9558
24.813
7.4575
0.85825
0.9459
2024-01-22
1.0890
160.95
1.9558
24.758
7.4585
0.85575
0.9458
2024-01-23
1.0872
160.88
1.9558
24.824
7.4574
0.85493
0.9446
2024-01-24
1.0905
160.46
1.9558
24.786
7.4568
0.85543
0.9415
Row or column-wise function application
df.apply(...) with functions returning scalars (“reduce”)
df.agg(['mean','median',lambda col: col.max(), maximum_plus_two ], axis=1) # here applying this aggregation functions to rows does not really make sense
/home/pierro/mambaforge/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1215: RuntimeWarning:
Mean of empty slice
/home/pierro/mambaforge/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1215: RuntimeWarning:
Mean of empty slice
/home/pierro/mambaforge/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1215: RuntimeWarning:
Mean of empty slice
/home/pierro/mambaforge/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1215: RuntimeWarning:
Mean of empty slice
mean
median
<lambda>
maximum_plus_two
Time
2024-01-18
28.275047
1.9558
160.89
162.89
2024-01-19
28.327021
1.9558
161.17
163.17
2024-01-22
28.287550
1.9558
160.95
162.95
2024-01-23
28.286276
1.9558
160.88
162.88
2024-01-24
28.220861
1.9558
160.46
162.46
...
...
...
...
...
2024-04-16
28.865143
1.9558
164.54
166.54
2023-11-07
NaN
NaN
NaN
NaN
2023-11-08
NaN
NaN
NaN
NaN
2023-11-06
NaN
NaN
NaN
NaN
2023-11-09
NaN
NaN
NaN
NaN
66 rows × 4 columns
Different aggregation functions to different columns
Entry-wise application of arbitrary functions with .map
# entry-wise function applicationdf.USD.map(lambda u: "more than 1"if u>1else"less than 1") # convert entries to string
Time
2024-01-18 more than 1
2024-01-19 more than 1
2024-01-22 more than 1
2024-01-23 more than 1
2024-01-24 more than 1
...
2024-04-16 more than 1
2023-11-07 less than 1
2023-11-08 less than 1
2023-11-06 less than 1
2023-11-09 less than 1
Name: USD, Length: 66, dtype: object
# convert to string and replace dot with the text -DOT-df.USD.map(lambda u: str(u).replace('.', '-DOT-'))
Time
2024-01-18 1-DOT-0875
2024-01-19 1-DOT-0887
2024-01-22 1-DOT-089
2024-01-23 1-DOT-0872
2024-01-24 1-DOT-0905
...
2024-04-16 1-DOT-0637
2023-11-07 nan
2023-11-08 nan
2023-11-06 nan
2023-11-09 nan
Name: USD, Length: 66, dtype: object
df.expanding().max() # useful to compute the highest exchange rate so far since 2023-11-06
USD
JPY
BGN
CZK
DKK
GBP
CHF
Time
2024-01-18
1.0875
160.89
1.9558
24.734
7.4571
0.85773
0.9432
2024-01-19
1.0887
161.17
1.9558
24.813
7.4575
0.85825
0.9459
2024-01-22
1.0890
161.17
1.9558
24.813
7.4585
0.85825
0.9459
2024-01-23
1.0890
161.17
1.9558
24.824
7.4585
0.85825
0.9459
2024-01-24
1.0905
161.17
1.9558
24.824
7.4585
0.85825
0.9459
...
...
...
...
...
...
...
...
2024-04-10
1.0939
164.97
1.9558
25.460
7.4605
0.85846
0.9846
2024-04-11
1.0939
164.97
1.9558
25.460
7.4605
0.85846
0.9846
2024-04-12
1.0939
164.97
1.9558
25.460
7.4605
0.85846
0.9846
2024-04-15
1.0939
164.97
1.9558
25.460
7.4606
0.85846
0.9846
2024-04-16
1.0939
164.97
1.9558
25.460
7.4609
0.85846
0.9846
62 rows × 7 columns
Prediction of the value at the next timepoint, and avoiding contamination
df.rolling(window=2, closed='left').mean()
USD
JPY
BGN
CZK
DKK
GBP
CHF
Time
2024-01-18
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2024-01-19
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2024-01-22
1.08810
161.030
1.9558
24.7735
7.45730
0.857990
0.94455
2024-01-23
1.08885
161.060
1.9558
24.7855
7.45800
0.857000
0.94585
2024-01-24
1.08810
160.915
1.9558
24.7910
7.45795
0.855340
0.94520
...
...
...
...
...
...
...
...
2024-04-10
1.08450
164.700
1.9558
25.3670
7.45890
0.857290
0.98130
2024-04-11
1.08635
164.930
1.9558
25.3740
7.45920
0.855890
0.98145
2024-04-12
1.07945
164.535
1.9558
25.3800
7.45990
0.855200
0.97985
2024-04-15
1.06905
163.670
1.9558
25.3645
7.46035
0.854745
0.97515
2024-04-16
1.06540
163.605
1.9558
25.3305
7.46045
0.854145
0.97205
62 rows × 7 columns
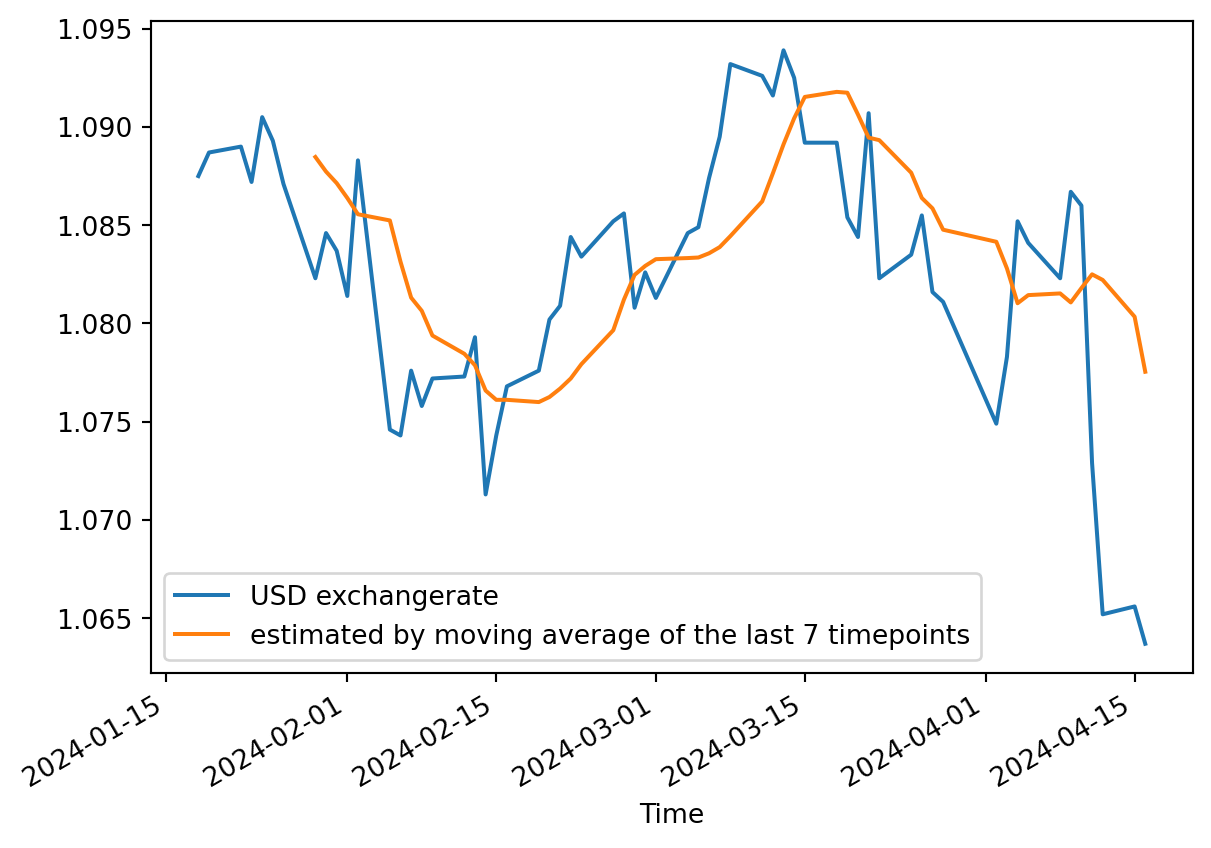
Example: predicting the current points with the average of the six previous (excluding the current point)
df['USD'].plot(label='USD exchangerate')df['USD'].rolling(window=7, closed='left').mean().plot( label='estimated by moving average of the last 7 timepoints')plt.legend()
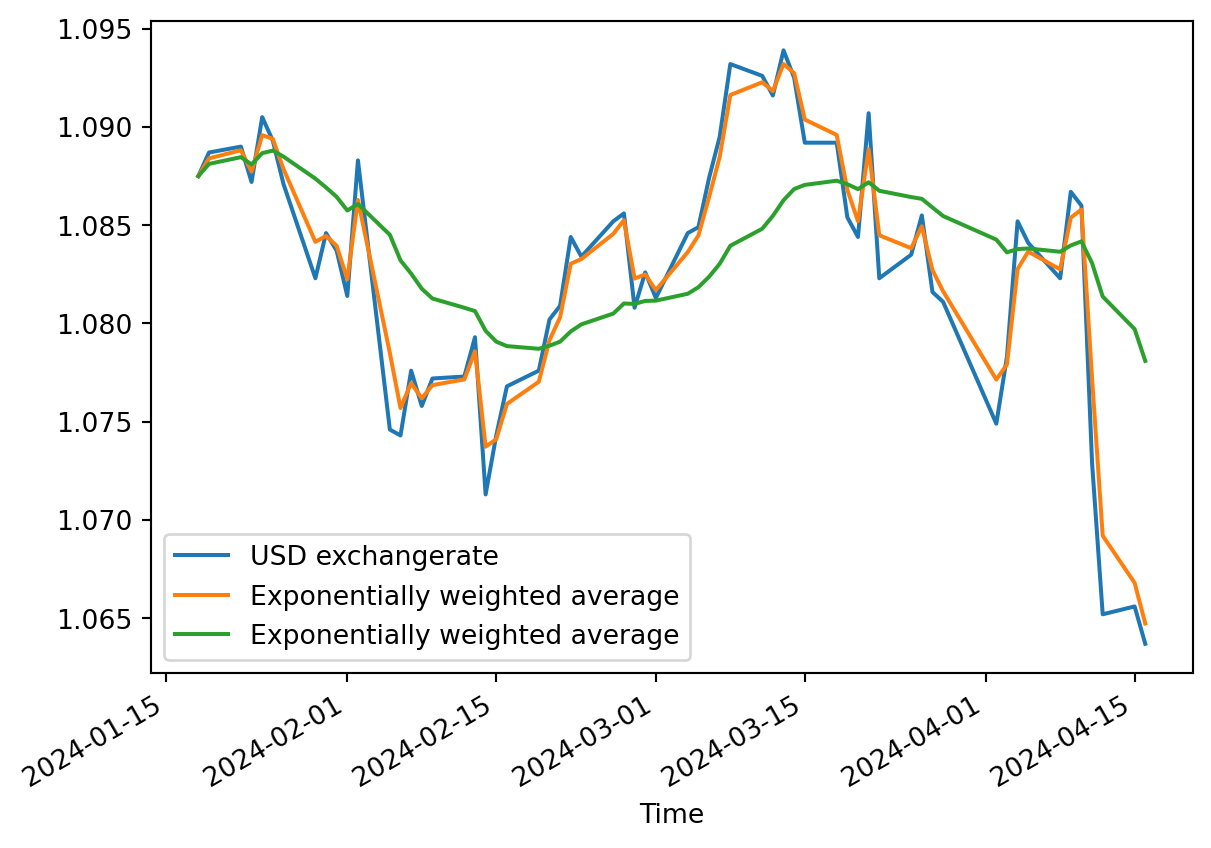
EWM: exponential moving window
only a small number of aggregation functions are implemented for exponential weighted moving avererages: https://pandas.pydata.org/docs/reference/window.html#exponentially-weighted-window-functions
# discard groups with any missing value in body_mass_g or bill_length_mm columnsgrouped.filter(lambda d: true_if_no_missing_value(d['body_mass_g']) and true_if_no_missing_value(d['bill_length_mm']))
species
island
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g
sex
30
Adelie
Dream
39.5
16.7
178.0
3250.0
Female
31
Adelie
Dream
37.2
18.1
178.0
3900.0
Male
32
Adelie
Dream
39.5
17.8
188.0
3300.0
Female
33
Adelie
Dream
40.9
18.9
184.0
3900.0
Male
34
Adelie
Dream
36.4
17.0
195.0
3325.0
Female
...
...
...
...
...
...
...
...
215
Chinstrap
Dream
55.8
19.8
207.0
4000.0
Male
216
Chinstrap
Dream
43.5
18.1
202.0
3400.0
Female
217
Chinstrap
Dream
49.6
18.2
193.0
3775.0
Male
218
Chinstrap
Dream
50.8
19.0
210.0
4100.0
Male
219
Chinstrap
Dream
50.2
18.7
198.0
3775.0
Female
124 rows × 7 columns
Transformation: assign the group average for missing values
from pandas.api.types import is_numeric_dtype# impute the mean, over each group, for all numeric columnsgrouped.transform(lambda x: x.fillna(value=x.mean()) if is_numeric_dtype(x) else x)